-
2026-02-12:Released TacZip codebase. Inference: inference.md Evaluation: evaluation.md Train: training_compressive_encoder.md and training_token_embedding.md.
-
2026-02-12: TacZip training and evaluation datasets are available on Hugging Face: TacZip-Data.
-
2026-02-03: ⚡Released task aware context compression model: TacZip-Qwen3-8b and TacZip-Llama2-7b.
-
2026-01-21: We release the code for FlexRAG. Inference: inference.md Evaluation: evaluation.md Train: training.md Paper: FlexRAG.
LightRAG is a lightweight and efficient retrieval-augmented generation (RAG) framework that reduces compute overhead while maintaining strong generation quality. Instead of storing and attending to full embeddings of large contexts, it applies latent context compression, enabling scalable and efficient generation. The context is first converted into a compressive embedding and then down-sampled based on a target compression ratio. This ratio can be flexibly allocated in various ways, e.g., according to priority.
LightRAG is built around four core design principles:
- Flexible compression ratios Supports arbitrary compression ratios, allowing users to trade off efficiency and accuracy based on task and resource constraints.
- Selective compression Allocates compression budgets selectively, preserving semantically important information while keeping only a minimal amount of auxiliary context.
- Unified multi-task compression Compresses contexts from different tasks into a shared latent space, enabling efficient handling of heterogeneous and multi-task data.
- Efficiency–quality balance Explicitly balances computational efficiency and generation quality, ensuring performance remains stable even under aggressive compression.
The project includes two solutions:
- TacZip — Delivers task-aware context compression with fine-grained, token-level ratio allocation.
- FlexRAG — Provides flexible context adaptation for question‑answering tasks.
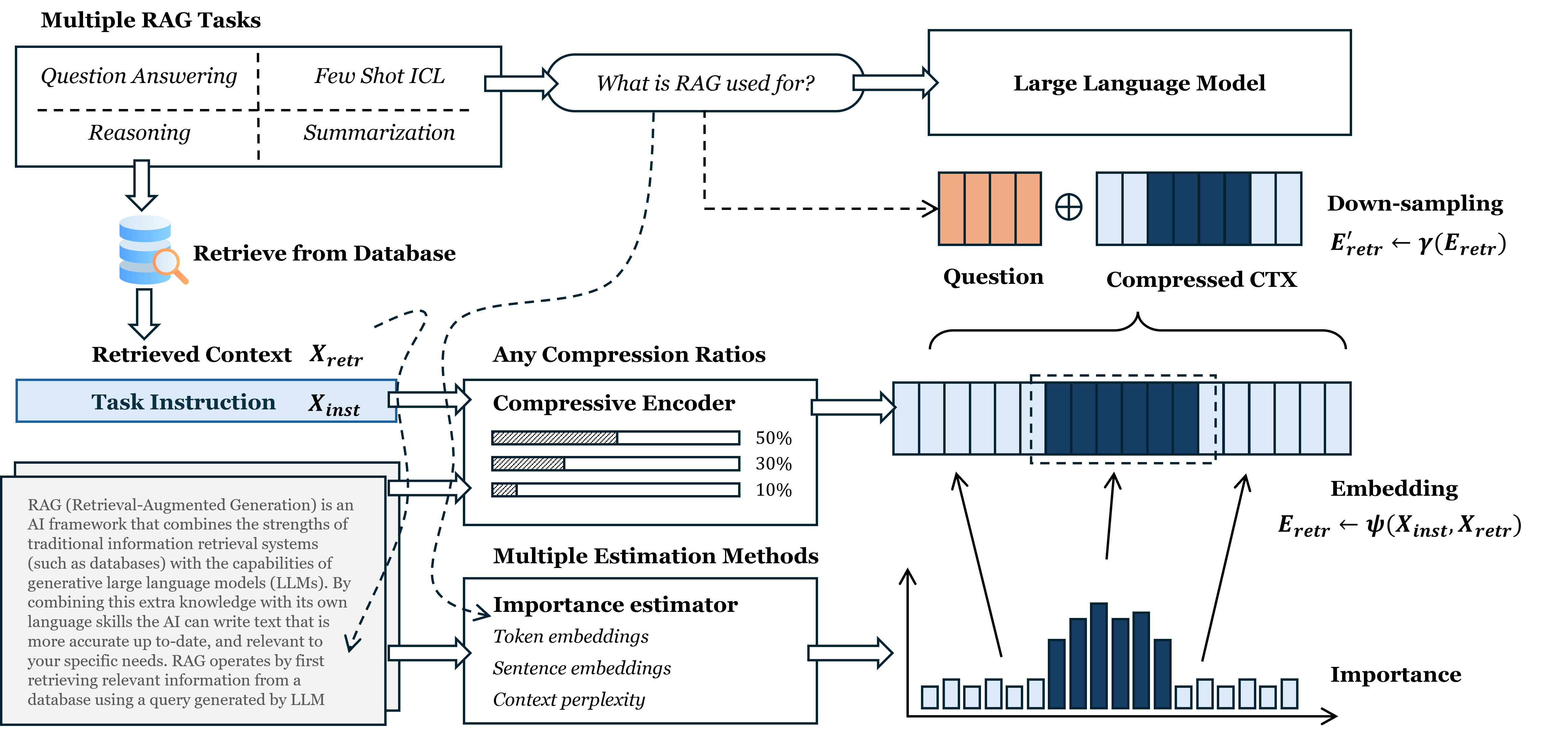
Overview of TacZip.
@inproceedings{wu2025lighter,
title={Lighter and better: Towards flexible context adaptation for retrieval augmented generation},
author={Wu, Chenyuan and Shao, Ninglu and Liu, Zheng and Xiao, Shitao and Li, Chaozhuo and Zhang, Chen and Wang, Senzhang and Lian, Defu},
booktitle={Proceedings of the Eighteenth ACM International Conference on Web Search and Data Mining},
pages={271--280},
year={2025}
}